Versions:7.1+
Apache Kafka is an open source data streaming platform that provides handling for real-time data feeds. Confluent offers the open-source KSQL engine which supports SQL-like querying of Kafka, to which a JDBC connection can be made using the KSQL open-source JDBC driver. This article discusses of some of the various methods of querying data from a Kafka stream or table via JDBC from QuerySurge, and a discussion of query termination (especially important in the context of Kafka).
![]() Note: It is important to be aware that KSQL itself is a separate open-source effort from the KSQL JDBC driver. KSQL is sponsored by Confluent, while the KSQL JDBC driver is a community open-source project. The JDBC driver is a work-in-progress relative to KSQL, and therefore syntax options that are available in KSQL may not be available via driver-based queries.
Note: It is important to be aware that KSQL itself is a separate open-source effort from the KSQL JDBC driver. KSQL is sponsored by Confluent, while the KSQL JDBC driver is a community open-source project. The JDBC driver is a work-in-progress relative to KSQL, and therefore syntax options that are available in KSQL may not be available via driver-based queries.
![]() Note: To set up a connection to your KSQL instance from QuerySurge, see this Knowledge Base article.
Note: To set up a connection to your KSQL instance from QuerySurge, see this Knowledge Base article.
Topics, Tables and Streams
Kafka is populated by data from messages that are sent by producers to Kafka, and are published into Kafka topics. Topics are denoted by a category or feed name where these messages are published and stored. The data is stored as an unbounded sequence of key-value pairs. These pairs are stored in raw byte arrays. Below is a sample DDL for a topic.
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 1 --topic test
A stream is a topic with a schema, i.e., the key-value pairs are no longer byte arrays but have specified types defined by the schema. Below is a sample DDL for a stream; note how the ddl imposes data types on the stream data.
CREATE STREAM TEST_STREAM (userid BIGINT, location VARCHAR) WITH (KAFKA_TOPIC='test', VALUE_FORMAT='DELIMITED');
A table is a normal table that can be derived from a topic or aggregate a stream. Tables represent the current state of the topic or stream as of the most recent, processed message. Below is a sample DDL for a table aggregating a stream.
CREATE TABLE TEST_TABLE AS SELECT userid, location, COUNT(*) AS TOTAL FROM TEST_STREAM
GROUP BY userid, location;
![]() Note: If you are new to Kafka, you can start with this introductory article.
Note: If you are new to Kafka, you can start with this introductory article.
KSQL Queries and Query Termination
You can query data from your KSQL tables or streams using QuerySurge QueryPairs, using the SQL dialect supported by the KSQL driver. There are two major differences between querying standard relational databases and Kafka streams.
- The first is that a KSQL query is continuous. When working with stream data more often than not the user is concerned with the latest messages being processed on the cluster, so queries against streams and tables will, by default, point to the most recent record, i.e. at the end of the stream or table.
- The second is that by default queries are non-terminating; if you query a stream or table without any termination instruction, you'll notice that the query seems to "hang". The query is not truly hung, it is simply waiting for additional messages because there is no termination condition. The significant point is that KSQL queries don't automatically, by themselves, terminate and return in the same way that relational database queries return. The user must set up query termination instructions.
Query Termination Using a Limit
As noted, since KSQL queries are non-terminating, queries appear to hang while actually waiting for more data. KSQL queries therefore require some type of explicit termination instruction. A simple termination instruction is the LIMIT clause. We can impose a limit on our query to terminate the request.
SELECT * FROM MY_TABLE
LIMIT 100
The above query will gather at most 100 records and terminate the query. If the offset is not set to the 'earliest' record, either globally or through the JDBC URL properties (see below) then the query will still set the pointer to the most recent record, and only terminate when at least 100 records have processed through the underlying topic or the timeout (if set) hits its limit.
Query Termination Using a Timeout
Another way to guarantee that a query terminates is by using a timeout value in the JDBC connection string. This forces the query to terminate after a given time period (units are in ms).
jdbc:ksql://192.168.0.37:8088?timeout=5000
The above connection URL terminates all KSQL queries after 5 seconds. The caveat here is that any new records being processed after that five second window in the underlying topic will not be included in the result set.
![]() Note: Use of the limit syntax and a timeout parameter together is supported, and is often advisable, as one gives query-level control over termination while the other offers connection-level control.
Note: Use of the limit syntax and a timeout parameter together is supported, and is often advisable, as one gives query-level control over termination while the other offers connection-level control.
Capturing old data - the KSQL Pointer
KSQL's pointer is by default at the most recent record, and therefore querying old data requires some extra handling. The KSQL option that governs this is the auto.offset.reset property. The default value is 'latest' (because the pointer is at the most recent record, and this is commonly what is needed); however it can be set to the 'earliest' value by adding the following to the ksql-server.properties (followed by a server restart).
auto.offset.reset=earliest
Alternatively, this property can be set on the JDBC URL:
jdbc:ksql://192.168.0.1:8088?properties=true&auto.offset.reset=earliest
This setup will gather historical data by starting at the earliest message in a topic for each query.
Finally, combining the timeout parameter and the offset parameters on the URL gives the following:
jdbc:ksql://192.168.0.1:8088?timeout=5000&properties=true&auto.offset.reset=earliest
Using KSQL Functions - Examples
For the most part, you should be able to call KSQL functions in your queries. Functions are called using the standard SQL syntax.
1. Timestamps
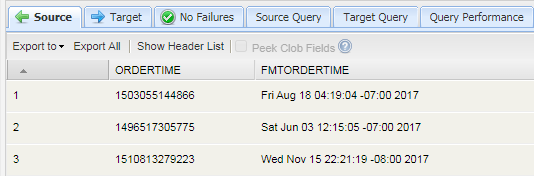
For converting a numeric time values to human-readable timestamps, KSQL uses the TIMESTAMPTOSTRING function. In the following example, the ordertime column (a BIGINT type in the underlying table) is converted to a custom, readable format via a formatting string:
SELECT ordertime,
TIMESTAMPTOSTRING(ordertime, 'EEE MMM dd HH:mm:ss ZZZZZ yyyy') as fmtordertime
from orders limit 50
Sample output from the query is:
Suppose your timestamp column is a VARCHAR or STRING type instead of a BIGINT. In this case, you can use a cast in your call to TIMESTAMPTOSTRING:
SELECT ordertime,
TIMESTAMPTOSTRING(CAST(ordertime AS BIGINT), 'EEE MMM dd HH:mm:ss ZZZZZ yyyy') as fmtordertime
from orders limit 50
2. Complex data types in KSQL via JDBC - JSON and STRUCTs
Complex types in KSQL are related to their JSON representations. Handling JSON strings is done with the EXTRACTJSONFIELD function. Consider the address field in the following stream:
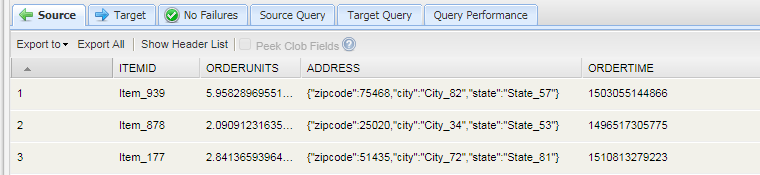
Note that the ADDRESS field, typed as a STRUCT but represented in the stream as a VARCHAR) is a JSON-formatted string. The EXTRACTJSONFIELD function can be used to handle the JSON fields individually, as illustrated in the following query and the data it returns:
SELECT itemId
, EXTRACTJSONFIELD(address,'$.city') AS city
, EXTRACTJSONFIELD(address,'$.state') AS state
, EXTRACTJSONFIELD(address,'$.zipcode') AS zipcode
from orders limit 50
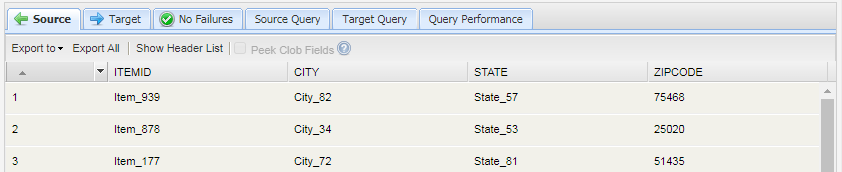
 Note: The same information might be captured not as a JSON-formatted string, but as a KSQL STRUCT with three fields. Presently, the KSQL JDBC driver does not support the KSQL dereferencing syntax '->', so a query of the sort: SELECT address->city FROM... does not work.
Note: The same information might be captured not as a JSON-formatted string, but as a KSQL STRUCT with three fields. Presently, the KSQL JDBC driver does not support the KSQL dereferencing syntax '->', so a query of the sort: SELECT address->city FROM... does not work.
3. Complex data types in KSQL via JDBC - ARRAYs and MAPs
Array and Map types can be handled via standard syntax: array elements are accessed by integer index and map elements are accessed by field names. If no index is provided, as with STRUCTs, the entity is returned as a JSON-like string. In the following examples, the INTERESTS column is an array type and the CONTACTINFO is a map.
SELECT ROWKEY
,REGISTERTIME
,USERID
,GENDER
,REGIONID
,INTERESTS
,CONTACTINFO
FROM users_ex LIMIT 2;
| REGISTERTIME | USERID | GENDER | REGIONID | INTERESTS | CONTACTINFO |
| 1496810307879 | User_9 | MALE | Region_6 | [Game, Sport] | {zipcode=94403, phone=6503349999, city=San Mateo, state=CA} |
A query accessing specific array elements and map fields follows:
SELECT REGISTERTIME
,USERID
,GENDER
,REGIONID
,INTERESTS[0]
,CONTACTINFO['phone']
,CONTACTINFO['city']
FROM users_ex LIMIT 2;
| REGISTERTIME | USERID | GENDER | REGIONID | INTERESTS[0] | CONTACTINFO['phone'] | CONTACTINFO['city'] |
| 1592422621107 | User_9 | NEUTRAL | Region_6 | Game | 6503349999 | San Mateo |
Note that both the array and map are accessed using square brackets, not parentheses. The array element is identified by index number, and the map field is identified by the field name, which must be enclosed in single quotes.