Apache Drill is a powerful tool for querying a variety of structured and partially structured data stores, including a number of different types of files. This article describes the use of QuerySurge with Drill for dealing with JSON files. Because Drill offers strong performance especially with large files, for QuerySurge data testing and verification that involves big files, Drill should be considered.
 Note: You can get the setup basics and background for Apache Drill in our Knowledge Base articles about Drill installation and setup on Windows, or on Linux, and on Drill Storage Plugins.
Note: You can get the setup basics and background for Apache Drill in our Knowledge Base articles about Drill installation and setup on Windows, or on Linux, and on Drill Storage Plugins.
Drill Configuration for JSON Data Files
In order to configure Drill for a JSON data file, the following configuration tasks need to be performed:
- Choose a Storage Plugin that defines the file format to modify - for JSON files this usually is the dfs plugin.
- Modify the plugin JSON for the proper file extension for your file, via the extensions property.
Storage Plugin Configuration
The default configuration for JSON data files with the dfs plugin is for a Flat File with a ".json" extension and the standard comma delimiter:
"json": {
"type": "json",
"extensions": [
"json"
]
}, ...
Typically, this requires no modification, beyond a possible change in the file extension. This configuration would apply to a standard file such as the following:
sample.json:
{"id":1,"animal":"dog","weight":35.2}
{"id":2,"animal":"cat","weight":8.4}
{"id":3,"animal":"pigeon","weight":1.9}
{"id":4,"animal":"fish","weight":3.3}
{"id":5,"animal":"horse","weight":2200.0}
Handling numbers in JSON
When reading numerical values from a JSON file, Drill distinguishes integers from floating point numbers by the presence or absence of a decimal point in a string of digits. If numbers in a JSON map or array appear both with and without a decimal point, such as 0 and 0.0, Drill throws a schema change error.
There are two Drill settings properties that can be used to avoid this:
json.read_numbers_as_double - Reads numbers from JSON files with or without a decimal point as DOUBLE.
If json.read_numbers_as_double is set to 'true', all numbers in your JSON will be typed as DOUBLE. In your SQL, you'll need to cast number columns that you want to handle as numeric types other than DOUBLE to other numerical types.
json.all_text_mode - Reads all data from JSON files as VARCHAR.
If json.all_text_mode is set to 'true', all values in your JSON will be typed as VARCHAR. In your SQL, you'll need to cast numbers from VARCHAR to numerical data types, where desired.
You can activate either one of these modes, via the Drill Options page or by using the Drill sqlline interactive shell. Setting either of these properties (not both!!) avoids errors thrown by Drill when a JSON file contains mixed numeric types.
Note: If you use the Drill Options page (at: http://<your-drill-server>:8047/options), set either json.read_numbers_as_double or json.all_text_mode to 'true'. If you use the Drill sqlline interactive shell to set your number handling, issue either of these commands : ALTER SESSION SET `store.json.read_numbers_as_double` = true;
or:ALTER SESSION SET `store.json.all_text_mode` = true;
QuerySurge and Drill with JSON Data Files
Deploy the Drill JDBC Driver
Make sure that you've deployed the Apache Drill JDBC driver to your QuerySurge Agents. See the Deploy the Drill JDBC Driver discussion in either of the installation articles (Windows or Linux articles) for instructions if you haven't deployed the driver yet.
Create a QuerySurge Connection to Drill
To create a new Drill Connection in QuerySurge, use the Connection Extensibility feature of the Connection Wizard. You can find a description of how to use Extensibility in this article. For this example suppose our file exists at the following directory location:
C:\files\sample.json (Windows)
/files/sample.json (Linux)
There are a couple of ways to set up a QuerySurge Connection for Drill, depending on whether you want to specify the Storage Plugin on the Connection in the JDBC URL or in your SQL (see this article about Storage Plugins for more details):
Specify the Storage Plugin in the JDBC URL
To specify the Storage plugin in the JDBC URL, use the following syntax:
jdbc:drill:schema=dfs;drillbit=<server-or-IP>:<port>
Note: In this case, your query specifies only the file path: SELECT ... FROM `/files/sample.json`;
Specify the Storage Plugin in your SQL Query
To specify the Storage plugin in the SQL, use the following URL syntax (which omits the schema):
jdbc:drill:drillbit=<server-or-IP>:<port>
Note: In this case, your query specifies both the Storage Plugin and the file path SELECT ... FROM: dfs.`/files/sample.json`;
Basic Notes on Drill SQL for JSON Files
Let's consider a our sample JSON file from above. Recall that this file contains three key-value pairs per element (id, animal, weight). The key-value pairs are of types BIGINT, VARCHAR, and DOUBLE respectively.
The most basic SQL query for a JSON in Drill is no different than what is used for any basic query:
SELECT * FROM `/files/sample.json`;
If the read_numbers_as_double property is set, then all numbers will be interpreted as DOUBLE types. If you want a specific numeric column to have a different type (for example, the id column in our sample file), an explicit cast is required:
SELECT CAST(id AS BIGINT), animal, weight FROM `/files/sample.json`;
Or if the all_text_mode property is set, then all fields are considered text, and both the id column and the weight column could be cast to their appropriate numeric types:
SELECT CAST(id AS BIGINT) AS id, animal, CAST(weight AS DOUBLE) AS weight FROM `/files/sample.json`;
Note: In the FROM clause of your SELECT statement, the path to the JSON file is always relative to the root location property. The root location property is defined in the storage plugin. So, if the root location is /files, then SELECT * FROM `/data/myfile.json` refers to a file at: /files/data/myfile.json.
 Note: You can find the full documentation for the Drill SQL dialect in the Drill SQL Reference.
Note: You can find the full documentation for the Drill SQL dialect in the Drill SQL Reference.
Complex JSON
Using Drill, we can access map fields nested within maps. In this more complex example, the animal entries have an additional object property that holds additional information:
sample.json:
{
"id":1,
"animal":"dog",
"weight":35.2,
"etc": {
"habitat":"prairie",
"food":"meat",
"lifespan":12
}
}
{
"id":2,
"animal":"cat",
"weight":8.4,
"etc": {
"habitat":"woods",
"food":"fish",
"lifespan":5
}
}
You can use dot notation to query this JSON, to drill down to the level you are interested in:
SELECT
t.id
,t.animal AS Animal
,t.etc.habitat AS Habitat
,t.etc.food AS Food
,t.etc.lifespan AS Lifespan
FROM
`/files/sample.json` t;
Note: When dealing with nested arrays or JSON objects, using the all wildcard (*) returns an error.
There are additional Drill tools for handling complex JSONs: the kvgen() and the flatten() functions.
- kvgen() - Generates key/value pairs from complex data.
- flatten() - Breaks the list of key-value pairs into separate rows on which you can apply analytic functions.
In the following kvgen() example, we split the etc items into individual key-value pairs:
SELECT kvgen(etc) FROM `/files/sample.json` where id = 1;
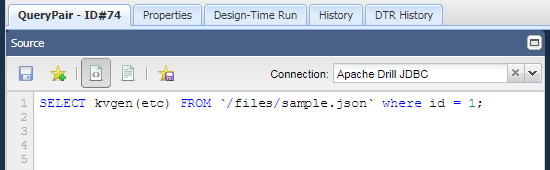
Results:
| 1 | {“key”:”habitat”,”value”:”prairie”},{“key”:”food”,”value”:”meat”},{“key”:”lifespan”,”value”:”12”} |
In the following flatten() example, takes a JSON array as an argument:
SELECT flatten(etc) FROM `/files/sample.json`;
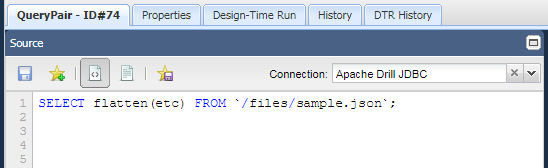
Results:
| 1 | {“key”:”habitat”,”value”:”prairie”} |
| 2 | {“key”:”food”,”value”:”meat”} |
| 3 | {“key”:”lifespan”,”value”:”12”} |
These two functions, kvgen() and the flatten(), are most commonly used in conjunction to pull all the values from within the nested arrays alongside root values.
SELECT t.name, t.registered.key, t.registered.`value`
FROM
(SELECT name, flatten(kvgen(etc)) AS registered
FROM dfs.`/files/sample.json`) t;
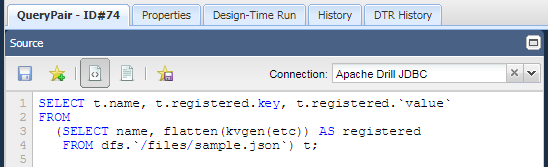
Results:
| 1 | dog | habitat | prairie |
| 2 | dog | food | meat |
| 3 | dog | lifespan | 12 |
| 4 | cat | habitat | woods |
| 5 | cat | food | fish |
| 6 | cat | lifespan | 5 |
Note: For a discussion of advanced Drill techniques with JSON, see this article.
Special Topics
Dot Notation
As noted, you can use dot notation in your SQL SELECT statements to locate specific JSON objects. Drill assumes that a name with no dot is the name of a field, while a name with two parts separated by a dot is in the format: "table.field".
For example, suppose records in myfile.json have a geometry field with a subfield x. The following Drill query is successful:
SELECT geometry FROM dfs.`some-file.json`;
However, the following query results in an error because there is no table named geometry.
SELECT geometry.x from dfs.`some-file.json`;
A table alias for the query resolves the problem:
SELECT tbl.geometry.x FROM dfs.`some-file.json` tbl;
Very Large JSON objects
Currently, Drill manages very large JSON objects, such as a gigabit-sized JSON files, only with difficulty. Finding the beginning and end of records can be time consuming and may require scanning the whole file. If you have this situation, the best recommendation is to use a tool to split the JSON file into smaller chunks of 64-128MB or 64-256MB initially until you know the total data size and node configuration. Keep the JSON objects intact in each file. A distributed file system, such as HDFS, is recommended over trying to manage file partitions.
For a complete list of Drill limitations with JSON and their workarounds, see this discussion.