Organizations using Azure Data Lake Storage (ADLS) often require testing of ADLS data assets with QuerySurge. However, ADLS does not natively offer access via JDBC, which QuerySurge requires. Apache Drill is a powerful tool for querying a variety of structured and partially structured data stores, including a number of different types of files. This article describes the use of QuerySurge with Drill to access and analyze flat files stored in Azure Data Lake Storage Gen2.
Because there are two separate authentication methods for ADLS, and sub-options within those methods, we've outlined the article below, to aid in choosing which combination of Authentication Method and Option will be correct for your organization.
- Drill Installation
-
Drill Configuration for Azure Data Lake Storage
- Deploy Azure drivers to Drill
- Configure Authentication in Azure
- QuerySurge, Drill and Azure Data Lake Storage
Drill Installation
You can get the setup basics and background for Apache Drill in our Knowledge Base articles about Drill installation and setup on Windows, or on Linux, and on Drill Storage Plugins. Once you have Drill installed, you can configure your installation to connect to ADLS.
Drill Configuration for Azure Data Lake Storage
1. Deploy Azure drivers to Drill
Drill needs several jar files to access various Azure services. These files need to be copied to the <Drill Installation Directory>\jars\3rdparty directory.
If you are on Windows, download the jar files using the following links and copy them to the directory:
hadoop-azure-3.3.0.jar
For Drill on Linux, you can use the following commands to download the drivers:
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure/3.3.0/hadoop-azure-3.3.0.jar
wget https://repo1.maven.org/maven2/com/microsoft/azure/azure-storage/8.6.5/azure-storage-8.6.5.jar
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-common/3.3.0/hadoop-common-3.3.0.jar
2. Configure Authentication in Azure
Azure Datalake Storage Gen2 provides supports a few different methods of authentication. This section walks you through the process of setting up Drill authentication to a Gen2 capable Azure Datalake Storage Account. There are two methods to configure authentication:
- Method 1: Access an Azure Data Lake Storage Gen2 account directly using the Storage Account Access Key
- Method 2: Access an Azure Data Lake Storage Gen2 account directly with OAuth 2.0 using the Service Principal
Authentication Method 1: Access an Azure Data Lake Storage Gen2 account directly using the storage account access key
Acquire an Access Key for the Storage Account
Included with an Azure Data Lake Gen2 Storage Account is the option to authenticate applications using the Storage Account's Access Keys. In order for Drill to access your ADLS Gen2 Storage Account, you will need to acquire an Access Key from the Storage account in the Azure Portal.
To find this, Navigate to the Storage Account in the Azure Portal, and click on Access Keys in the left-hand side menu as seen in the screenshot below.
From there, copy the first Key from this page.
Configuring Drill with Access Key Authentication
Once you have acquired the necessary authentication information from Azure, you have two options as to where to configure the connection in Apache Drill. This section will walk you through both options.
- Option 1: Set up Access Key authentication directly in the Storage Plug-in configuration
- Option 2: Set up Access Key authentication in the Apache Drill core-site.xml configuration file.
Option 1: Storage Plug-in Configuration
Connect to the Drill console by navigating to http://<IP Address>:8047 in a browser. Once you are there click on the Storage tab, and then at the bottom of the screen you will see a New Storage Plugin section where you can register a new data source. Enter a friendly name for the ADLS data (source since this will be used in your SQL statements to reference the data in the Data Lake). Click on the Create button.
A large text box will open up where you need to paste the JSON configuration below. However, you'll first need to modify the URL in this JSON. For Azure Datalake Storage Gen2, the URL format is the following:
abfs[s]1://<file_system>2@<account_name>3.dfs.core.windows.net/<path>4/<file_name>5
-
Scheme identifier: The
abfsprotocol is used as the scheme identifier. You have the option to connect with or without a Transport Layer Security (TLS), previously known as Secure Sockets Layer (SSL), connection. Useabfssto connect with a TLS connection. -
File system: The parent location that holds the files and folders. This is the same as Containers in the Azure Storage Blobs service.
-
Account name: The name given to your storage account during creation.
-
Paths: (Optional) A forward slash delimited (
/) representation of the directory structure. -
File name: (Optional) The name of the individual file. This parameter is optional if you are addressing a directory.
Replace FILESYSTEM with the parent location (Container) that holds the files and folders in your Storage Account, YOURDATALAKEACCOUNT with that of your Gen2 capable Storage Account, and ACCESS_KEY with the Storage Account's Access Key obtained earlier from the Azure Portal. This can be found in the Azure Portal by navigating to that resource, the name will be displayed in the header.
{
"type": "file",
"enabled": true,
"connection": "abfs://{FILESYSTEM}@{YOURDATALAKEACCOUNT}.dfs.core.windows.net/root",
"config": {
"fs.azure.account.key.{YOURDATALAKEACCOUNT}.dfs.core.windows.net": "{ACCESS_KEY}",
"fs.azure.account.auth.type": "SharedKey"
},
"workspaces": {
"root": {
"location": "/",
"writable": false,
"defaultInputFormat": null
},
"tmp": {
"location": "/tmp",
"writable": true,
"defaultInputFormat": null
}
},
"formats": {
"psv": {
"type": "text",
"extensions": [
"tbl"
],
"delimiter": "|"
},
"csv": {
"type": "text",
"extensions": [
"csv"
],
"extractHeader": true,
"delimiter": ","
},
"tsv": {
"type": "text",
"extensions": [
"tsv"
],
"delimiter": "\t"
},
"parquet": {
"type": "parquet"
},
"excel": {
"type": "excel"
},
"json": {
"type": "json",
"extensions": [
"json"
]
},
"avro": {
"type": "avro"
},
"sequencefile": {
"type": "sequencefile",
"extensions": [
"seq"
]
},
"csvh": {
"type": "text",
"extensions": [
"csvh"
],
"extractHeader": true,
"delimiter": ","
}
}
}
Click Create to register the data source in Azure Data Lake Store for further use in querying within Drill.
Option 2: Drill's core-site.xml
Edit or create the core-site.xml in conf directory under Drill home. Add the following lines within the element. Replace value for {ACCESS_KEY} and {STORAGE_ACCOUNT} in the configuration segment below.
<property>
<name>fs.azure.account.auth.type</name>
<value>SharedKey</value>
</property>
<property>
<name>fs.azure.account.key.{STORAGE_ACCOUNT}.dfs.core.windows.net</name>
<value>{ACCESS_KEY}</value>
</property>
Connect to Drill console by navigating to http://<IP Address>:8047 in a browser. Once you are there click on the Storage tab and then at the bottom of the screen you will see a New Storage Plugin section where you can register a new data source. Enter a friendly name for the ADLS data source since this will be used in your SQL statements to references the data in the Data Lake. Click on the Create button.
A large text box will open up where you need to paste the following JSON configuration. However, you'll first need to modify the URL in this JSON. With Azure Datalake Storage Gen2, the URL Format is the following:
abfs[s]1://<file_system>2@<account_name>3.dfs.core.windows.net/<path>4/<file_name>5
-
Scheme identifier: The
abfsprotocol is used as the scheme identifier. You have the option to connect with or without a Transport Layer Security (TLS), previously known as Secure Sockets Layer (SSL), connection. Useabfssto connect with a TLS connection. -
File system: The parent location that holds the files and folders. This is the same as Containers in the Azure Storage Blobs service.
-
Account name: The name given to your storage account during creation.
-
Paths: (Optional) A forward slash delimited (
/) representation of the directory structure. -
File name: (Optional) The name of the individual file. This parameter is optional if you are addressing a directory.
Replace FILESYSTEM with the parent location (Container) that holds the files and folders in your Storage Account and YOURDATALAKEACCOUNT with that of your Gen2 capable Storage Account. This can be found in the Azure Portal by navigating to that resource, the name will be displayed in the header.
{
"type":"file",
"enabled":true,
"connection":"abfs://FILESYSTEM@YOURDATALAKEACCOUNT.dfs.core.windows.net/root",
"config":null,
"workspaces":{
"root":{
"location":"/",
"writable":false,
"defaultInputFormat":null
},
"tmp":{
"location":"/tmp",
"writable":true,
"defaultInputFormat":null
}
},
"formats":{
"psv":{
"type":"text",
"extensions":[
"tbl"
],
"delimiter":"|"
},
"csv":{
"type":"text",
"extensions":[
"csv"
],
"extractHeader":true,
"delimiter":","
},
"tsv":{
"type":"text",
"extensions":[
"tsv"
],
"delimiter":"\t"
},
"parquet":{
"type":"parquet"
},
"excel": {
"type": "excel"
},
"json":{
"type":"json",
"extensions":[
"json"
]
},
"avro":{
"type":"avro"
},
"sequencefile":{
"type":"sequencefile",
"extensions":[
"seq"
]
},
"csvh":{
"type":"text",
"extensions":[
"csvh"
],
"extractHeader":true,
"delimiter":","
}
}
}
Click Create to register the data source in Azure Data Lake Store.
 Note: The name you give your storage plugin will need to be used later when defining the connection URL or choosing a schema in your SQL statements.
Note: The name you give your storage plugin will need to be used later when defining the connection URL or choosing a schema in your SQL statements.
 Note: Any file types you would like to query must be included as an entry under the formats tag in the JSON.
Note: Any file types you would like to query must be included as an entry under the formats tag in the JSON.
Authentication Method 2: Access an Azure Data Lake Storage Gen2 account directly with OAuth 2.0 using the Service Principal
Register an Azure AD application and service principal that can access resources
For Drill to access your Azure Data Lake store, it must be added as an Active Directory web application with proper access to your files in the Azure portal. Follow instructions here to register an Application in Azure AD, and configure access to your Azure Data Lake resource.
Note: To create an Azure AD application, app registrations must be enabled in the Azure active directory. Navigate to the Azure Active Directory, select user settings and check the app registrations setting.
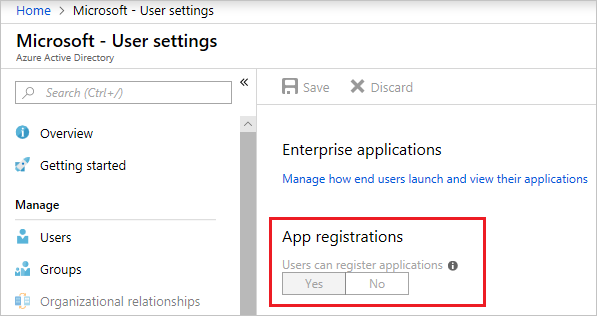
This value can only be set by an administrator. If set to Yes, any user in the Azure AD tenant can register an app. If the app registrations setting is set to No, only global administrators can register apps.
Once you have completed the steps, Registered an Application with Azure Active Directory, and configured access to your Storage Account, make note of the following values necessary to make the connection from Drill:
- Directory (tenant) ID
- Application (client) ID
- Client Secret
The Directory ID and Application ID are found on the Application's Overview section, as seen below:
You can create a Client Secret from the Application's Certificates & Secrets section, as seen below:
- From App registrations in Azure AD, select your application.
-
Select Certificates & secrets
-
Select Client secrets -> New client secret, Provide a description of the secret, and an expiration. When done, select Add.
-
Copy the value.
Configuring Drill with OAuth 2.0 Authentication
Once you have acquired the necessary authentication information from Azure, you have two options as to where to configure the connection in Apache Drill. This section will walk you through both options.
- Option 1: Set up OAuth-based authentication directly in the Storage Plug-in configuration
- Option 2: Set up OAuth-based authentication in the Apache Drill core-site.xml configuration file.
Option 1: Storage Plug-in Configuration
Connect to Drill console by navigating to http://<IP Address>:8047 in a browser. Once you are there click on the Storage tab and then at the bottom of the screen you will see a New Storage Plugin section where you can register a new data source. Enter a friendly name for the ADLS data source since this will be used in your SQL statements to references the data in the Data Lake. Click on the Create button.
A large text box will open up where you need to paste the following JSON configuration. However, you'll first need to modify the URL in this JSON. With Azure Datalake Storage Gen2, the URL Format is the following:
abfs[s]1://<file_system>2@<account_name>3.dfs.core.windows.net/<path>4/<file_name>5
-
Scheme identifier: The
abfsprotocol is used as the scheme identifier. You have the option to connect with or without a Transport Layer Security (TLS), previously known as Secure Sockets Layer (SSL), connection. Useabfssto connect with a TLS connection. -
File system: The parent location that holds the files and folders. This is the same as Containers in the Azure Storage Blobs service.
-
Account name: The name given to your storage account during creation.
-
Paths: (Optional) A forward slash delimited (
/) representation of the directory structure. -
File name: (Optional) The name of the individual file. This parameter is optional if you are addressing a directory.
Replace FILESYSTEM with the parent location (Container) that holds the files and folders in your Storage Account, YOURDATALAKEACCOUNT with that of your Gen2 capable Storage Account, and replace {APPLICATION(CLIENT)_ID}, {CLIENT_SECRET}, and {DIRECTORY(TENNANT)_ID} with their respective values obtained earlier from the Azure Portal. This can be found in the Azure Portal by navigating to that resource, the name will be displayed in the header.
{
"type":"file",
"enabled":true,
"connection":"abfs://{FILESYSTEM}@{YOURDATALAKEACCOUNT}.dfs.core.windows.net/root",
"config": {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "{APPLICATION(CLIENT)_ID}",
"fs.azure.account.oauth2.client.secret": "{CLIENT_SECRET}",
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/{DIRECTORY(TENNANT)_ID}/oauth2/token"
},
"workspaces":{
"root":{
"location":"/",
"writable":false,
"defaultInputFormat":null
},
"tmp":{
"location":"/tmp",
"writable":true,
"defaultInputFormat":null
}
},
"formats":{
"psv":{
"type":"text",
"extensions":[
"tbl"
],
"delimiter":"|"
},
"csv":{
"type":"text",
"extensions":[
"csv"
],
"extractHeader":true,
"delimiter":","
},
"tsv":{
"type":"text",
"extensions":[
"tsv"
],
"delimiter":"\t"
},
"parquet":{
"type":"parquet"
},
"excel": {
"type": "excel"
},
"json":{
"type":"json",
"extensions":[
"json"
]
},
"avro":{
"type":"avro"
},
"sequencefile":{
"type":"sequencefile",
"extensions":[
"seq"
]
},
"csvh":{
"type":"text",
"extensions":[
"csvh"
],
"extractHeader":true,
"delimiter":","
}
}
}
Click Create to register the data source in Azure Data Lake Store for further use in querying within Drill.
Option 2: Drill's core-site.xml
Edit or create the core-site.xml in conf directory under Drill home. Add the following lines within the element. Replace {APPLICATION(CLIENT)_ID}, {CLIENT_SECRET}, and {DIRECTORY(TENNANT)_ID} with their respective values obtained earlier from the Azure Portal.
<property>
<name>fs.azure.account.auth.type</name>
<value>OAuth</value>
</property>
<property>
<name>fs.azure.account.oauth.provider.type</name>
<value>org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.id</name>
<value>{APPLICATION(CLIENT)_ID}</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.secret</name>
<value>{CLIENT_SECRET}</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.endpoint</name>
<value>https://login.microsoftonline.com/{DIRECTORY(TENNANT)_ID}/oauth2/token</value>
</property>
Connect to Drill console by navigating to http://<IP Address>:8047 in a browser. Once you are there click on the Storage tab and then at the bottom of the screen you will see a New Storage Plugin section where you can register a new data source. Enter a friendly name for the ADLS data source since this will be used in your SQL statements to references the data in the Data Lake. Click on the Create button.
A large text box will open up where you need to paste the following JSON configuration. However, you'll first need to modify the URL in this JSON. With Azure Datalake Storage Gen2, the URL Format is the following:
abfs[s]1://<file_system>2@<account_name>3.dfs.core.windows.net/<path>4/<file_name>5
-
Scheme identifier: The
abfsprotocol is used as the scheme identifier. You have the option to connect with or without a Transport Layer Security (TLS), previously known as Secure Sockets Layer (SSL), connection. Useabfssto connect with a TLS connection. -
File system: The parent location that holds the files and folders. This is the same as Containers in the Azure Storage Blobs service.
-
Account name: The name given to your storage account during creation.
-
Paths: (Optional) A forward slash delimited (
/) representation of the directory structure. -
File name: (Optional) The name of the individual file. This parameter is optional if you are addressing a directory.
Replace FILESYSTEM with the parent location (Container) that holds the files and folders in your Storage Account and YOURDATALAKEACCOUNT with that of your Gen2 capable Storage Account. This can be found in the Azure Portal by navigating to that resource, the name will be displayed in the header.
{
"type":"file",
"enabled":true,
"connection":"abfs://FILESYSTEM@YOURDATALAKEACCOUNT.dfs.core.windows.net/root",
"config":null,
"workspaces":{
"root":{
"location":"/",
"writable":false,
"defaultInputFormat":null
},
"tmp":{
"location":"/tmp",
"writable":true,
"defaultInputFormat":null
}
},
"formats":{
"psv":{
"type":"text",
"extensions":[
"tbl"
],
"delimiter":"|"
},
"csv":{
"type":"text",
"extensions":[
"csv"
],
"extractHeader":true,
"delimiter":","
},
"tsv":{
"type":"text",
"extensions":[
"tsv"
],
"delimiter":"\t"
},
"parquet":{
"type":"parquet"
},
"excel": {
"type": "excel"
},
"json":{
"type":"json",
"extensions":[
"json"
]
},
"avro":{
"type":"avro"
},
"sequencefile":{
"type":"sequencefile",
"extensions":[
"seq"
]
},
"csvh":{
"type":"text",
"extensions":[
"csvh"
],
"extractHeader":true,
"delimiter":","
}
}
}
Click Create to register the data source in Azure Data Lake Store for further use in querying within Drill.
Note: The name you give your storage plugin will need to be used later when defining the connection URL or choosing a schema in your SQL statements.
Note: Any file types you would like to query must be included as an entry under the formats tag in valid JSON format.
QuerySurge, Drill and Azure Data Lake Storage
The previous steps have set up the Drill connection to ADLS. Now, as the final part of the setup, you'll connect QuerySurge to Drill, enabling QuerySurge to work with ADLS through the pipeline created by Drill.
Deploy the Drill JDBC Driver
Make sure that you've deployed the Apache Drill JDBC driver to your QuerySurge Agents. See the Deploy the Drill JDBC Driver discussion in either of the installation articles (Windows or Linux) for instructions if you haven't deployed the driver yet.
Create a Connection
To create a new Connection in QuerySurge, we use the Connection Extensibility feature of the Connection Wizard. You can find a full description of this procedure in this Knowledge Base article. Key points include the following:
- Navigate to: Administration > Connections > Add. Check "Advanced Mode" and choose "* All Other JDBC Connections (Connection Extensibility)" in the Data Source dropdown.
- For the Driver Class, enter: org.apache.drill.jdbc.Driver.
- For the Connection URL, enter:
jdbc:drill:drillbit=localhost;schema=dfs
The two properties used in the Connection URL are:
drillbit: The location of the Drill instance you set up, which can be specified by server name, IP address or 'localhost' (as in this example).
schema: The name of a Storage Plugin to handle our specific filetype. Storage Plugins are software modules that connect Drill to data sources. Apache Drill includes a Storage Plugin configuration named dfs that points to the local file system on your machine by default - this is the Storage Plugin used in the example above.
Note: Check out our Knowledge Base article on Storage Plugins for more detail.
Test your Drill JDBC Connection
Create a small CSV file called sample.csv and deploy it on an Agent box. Write a simple query to pull information from a basic CSV file called sample.csv. For a CSV file deployed to:
C:\Users\myuser\Documents\sample.csv
the Drill query has the following format:
SELECT ... FROM `/Users/myuser/Documents/sample.csv`
Note that the query defines the path to the file, but omits the partition label (C: in this example). Also, notice that forward-slashes (/) are used in the path instead of back-slashes (\), and that the path is enclosed with back-tics (`), not single quotes.
To complete our SELECT, another aspect of Drill syntax comes into play. In the default configuration for comma delimited files, Drill represents the file columns as elements of an array named "columns". Because of this, you must use the columns[n] syntax in the SELECT list:
SELECT columns[0] FROM `/Users/myuser/Documents/sample.csv`
Note: This syntax uses a zero-based index, so the first column is column 0.
You can set up a QueryPair in QuerySurge to use this query to test out your Drill Connection. The simplest way to set up the test is to use the same query for both Source and Target.
Note: You can find the full documentation for the Drill SQL dialect in the Drill SQL Reference. Specifics for querying a filesystem are found in this discussion.
Querying Flat Files In ADLS Gen2 with Drill
At this point, querying flat files within an Azure Data Lake Store Gen2 is identical to querying files on your local filesystem from Drill and requires both the same Storage Plugin edits and SQL syntax as when using the dfs Storage Plugin.
In the following example, we'll use a simple CSV file with four columns. Similar to using the dfs Storage Plugin to query local CSV files, the "columns[n]" zero-based index syntax can be used to query the file:
SELECT columns[0], columns[1] FROM azuredatalake.`sample.csv`;