QuerySurge Technical Whitepaper No. 8
Flat File SQL Joins
In many instances, an ETL process may use several flat files to load a target database table. In these cases, you may need to join these flat files in your SQL query to effectively compare the data. This will require a bit of extra setup in QuerySurge - you'll need to include separate table definitions (one for each file) in your schema file, which isn't supported in the standard Flat File approach in the Connection Wizard. You'll need to use the Connection Extensibility feature.
QuerySurge Schema File
Your QuerySurge schema file is an XML document with a root tag of <schema> and (ordinarily) a single child tag of <table>. In situations that necessitate a SQL join, you'll need to add <table> tags to the document for each file you'll reference in your query.
In the example below, the schema files contains table definitions for two character-delimited files (customers.csv and addresses.psv) and a fixed-width file (orders.dat).
<schema>
<table name="customers.csv" separator="," suppressHeaders="false">
<column name ="ID" type="Integer"/>
<column name ="OID" type="Varchar" size="64"/>
<column name ="FNAME" type="Varchar" size="64"/>
<column name ="LNAME" type="Varchar" size="64"/>
<column name ="USERID" type="Integer"/>
</table>
<table name="addresses.psv" separator="|" suppressHeaders="true">
<column name ="ID" pos="1" type="Integer"/>
<column name ="OID" pos="2" type="Varchar" size="64"/>
<column name ="STREET" pos="3" type="Varchar" size="64"/>
<column name ="CITY" pos="4" type="Varchar" size="64"/>
<column name ="STATE" pos="5" type="Varchar" size="64"/>
<column name ="ZIP" pos="6" type="Varchar" size="64"/>
</table>
<table name="orders.dat" separator="fixed" suppressHeaders="false">
<column name ="ID" begin="1" end="5" type="Integer"/>
<column name ="OID" begin="6" end="10" type="Varchar" size="64"/>
<column name ="ORDERID" begin="11" end="20" type="Long"/>
<column name ="PRICE" begin="21" end="30" type="Decimal" size="10" decimalCount="2"/>
</table>
</schema>
Creating the Connection
When creating your connection, you will not be able to utilize the built-in Flat File connection type in the Connection Wizard. Instead, you will need to use the Connection Extensibility feature. To do this, select the All Other JDBC Connections (Connection Extensibility) option from the drop-down menu.
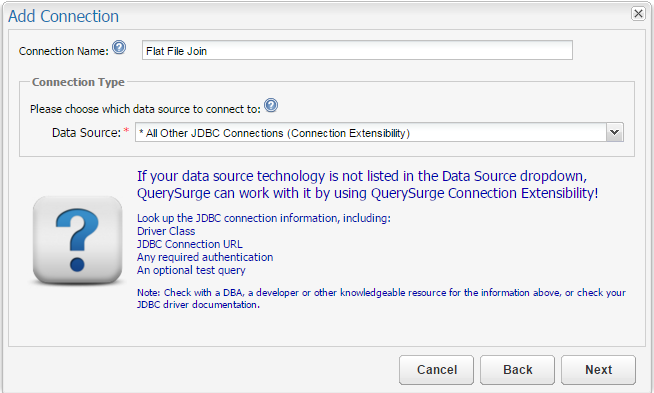
For your Driver Class, please enter jstels.jdbc.csv.CsvDriver2. If you did not select the Flat File drivers during your initial installation, you'll need to add them before continuing (Windows / Linux).
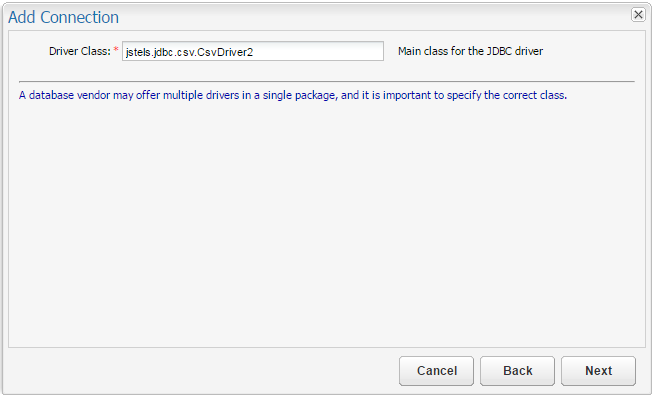
Lastly, you'll need to enter your Connection URL. This will depend on the location of your schema and data files, but will formatted like so: jdbc:jstels:csv:<path/to/data/files>?schema=<path/to/schema>/<schema_file>.xml&separator=,.
 Note: The separator in the URL is overridden by the separator values in the schema.xml, but it does need to be defined in the URL.
Note: The separator in the URL is overridden by the separator values in the schema.xml, but it does need to be defined in the URL.
Writing the SQL
When writing your SQL, you can join your files like so:
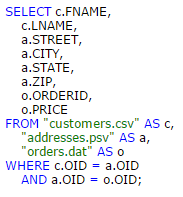
(WHERE clause JOIN syntax)
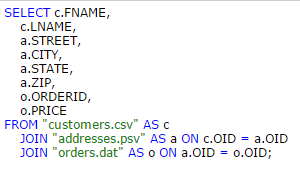
(standard JOIN syntax)