Versions:2.5+
- Comparing Data Sets
- Data Containing Keys in Source and Target
- Data with 'Implicit' Keys
- Data with No Keys - Duplicate Data
- Specifying Keys in QuerySurge
- How Key-based evaluations appear in QuerySurge
Comparing Data Sets
What does it mean to compare two sets of data? This is a basic question that QuerySurge deals with, and we review here how QuerySurge handles the different possibilities.
Shared Keys in Source and Target
The most powerful comparison between two sets of data can be done when you identify Shared Key column(s) for QuerySurge to use. Shared Key columns, for purposes of QuerySurge, are columns in which:
- Each key value is guaranteed to be unique
- The key values match between Source and Target for like rows.
An example of two data sets with matching keys is shown below:

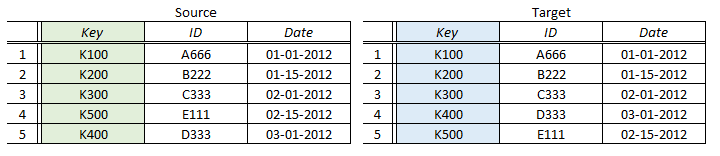
Because we have matching keys in both resultsets, we know affirmatively exactly which row on the Source side compares to each specific row on the Target side. This would be true regardless of the row order – (note that Source K400 is below Source K500, while the analogous rows in Target are sequential).
Data Failures Between Source and Target
Consider the following variation of our first resultsets.

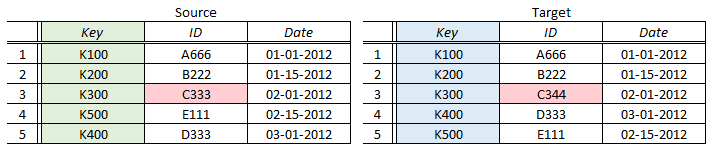
We’ve introduced two changes. First, you can see that the row with key K300 now has a failing condition – the Source and Target rows that are joined by this matching key have different data. QuerySurge will flag this as a Data Failure, and the Outcome for this QueryPair will appear accordingly in the QuerySurge Run Dashboard and in Reports.
In addition, the row order differs between Source and Target – the K400 and K500 rows are in “reverse” order in the Source resultset. QuerySurge will recognize the correct pairings of these two rows, and show that their data agrees.
 Best Practice It is a best practice, however, to use ORDER BY clauses on your queries – this will make your data sets much more readable, and could have impacts on how QuerySurge analyzes your data when you don’t have keys – see below.
Best Practice It is a best practice, however, to use ORDER BY clauses on your queries – this will make your data sets much more readable, and could have impacts on how QuerySurge analyzes your data when you don’t have keys – see below.
Non-matching Rows in Source and Target
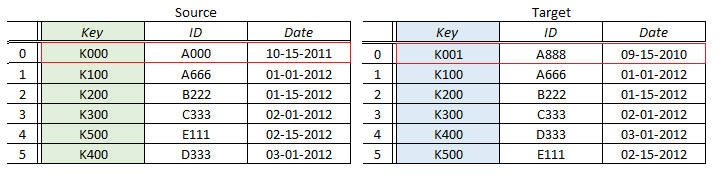
Now consider another situation: suppose that Source and Target do not contain identical sets of matching keys.


In this illustration, the source resultset contains the key K000, which has no pairing in the Target resultset. Because we have no matching key, we can’t compare this row to anything on the Target side. In QuerySurge terms, this is a Non-matching row on the Source side. Note that, in this example, there is also a Row Count Difference – the Source has 6 rows and the Target has 5 rows, so a Row Count Difference of 1 row will be reported.
The idea of Non-matching rows opens up multiple possibilities. Clearly, we could have Non-matching rows specific to the Target side just as we have illustrated on the Source side above.
In addition, we can have Non-matching rows on both the Source and Target simultaneously, without a Row Count Difference:

In this example, we have 1 Non-matching row on Source and 1 on Target. In this case, we have a total of 2 Non-matching rows, and because they are evenly distributed between Source and Target, the Row Count Difference is 0.
An important point to note is that when we have keys, the keys dominate the comparison, regardless of how the data looks. So, if two keys do not match, their rows cannot be compared – even if we otherwise might think that the row comparison is justified:

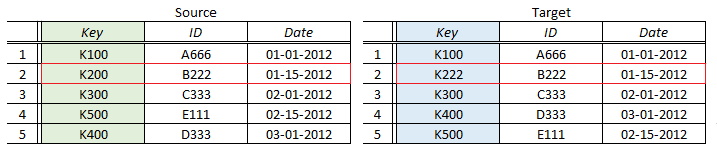
In the second row, the keys do not match – even though the data does match. Without the keys, we probably would conclude that the data sets are identical. With the keys, we know that we have 2 Non-matching rows – one in Source and one in Target – and 0 Data Failures.
Real Data
As you probably already know, real world data is rarely clean, and it will be likely that you’ll see both Data Failures and Non-matching rows in your resultsets in QuerySurge. So the following situation will likely occur:

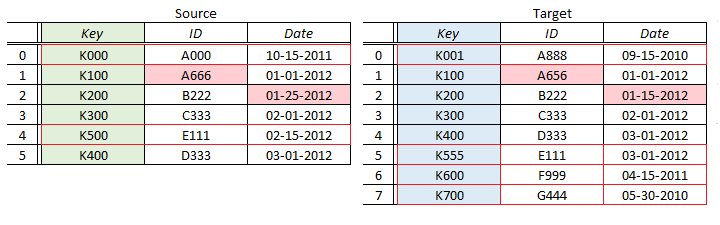
In this example, you can see that we have 2 Non-matching rows on the Source side, and 4 Non-matching rows on the Target. In addition, we have 2 Data Failures - a Data Failure on the K100 row and one on the K200 row. Finally, we have a Row Count Difference of 2 rows between Source and Target.
Data with ‘Implicit’ Keys
In some cases, you may not be able to write queries that have Shared Keys, but your data may have what we can call ‘implicit’ keys. This means that the rows in your resultsets have uniqueness by virtue of the data they contain.
A Key Assumption
In the example below, it looks as if both resultsets are the same. No row has a key, but all rows are unique within each set, and each row in the Source has an identical match in the Target. And, in fact, QuerySurge will treat them as if they are comparable sets of data, and will score a passing result for this QueryPair. It is important, however, to note that we are making a significant assumption here: that the like rows of data in Source and Target are comparable to each other. In this case, QuerySurge treats the data as if it has ‘implicit’ keys – composed of the data itself.

We are, in effect, assuming that if we could see the “hidden” keys for these resultsets, they would confirm our assumptions about the data. But that is not necessarily true; if we could “reveal” the “hidden” keys, we could be surprised, as in the following example:

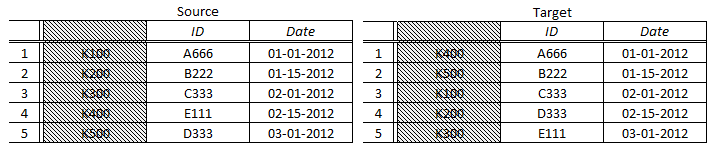
With the keys “revealed”, in this example there is no passing row comparison in this QueryPair – even though the data is the same in both Source and Target, the “hidden” keys say otherwise. The point is to underscore that QuerySurge makes an important assumption when we compare the data this way – about the relationship between rows in Source and Target. Clearly, QuerySurge can provide a much better data comparison with explicit keys. Shared Keys should be your default choice, if possible.
In the case above (with no knowledge of the "hidden" keys), QuerySurge will mark the QueryPair as a passing test, because of our working assumption.
Non-matching or Data Failures or Neither?
In addition, there is another important point to make: in a ‘key-less’ situation, QuerySurge can’t really tell the difference between Non-matching rows and rows with Data Failures. In the absence of Shared Keys, QuerySurge has no absolute way to tell which category a row falls into when data is not definitively aligned between Source and Target. So, QuerySurge does not offer this categorization when there are no keys. It will mark all mismatching data without flagging it as either Non-matching or Data Failure.
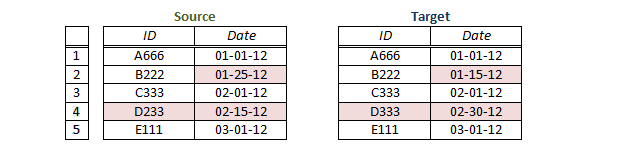
In the example below, we might be inclined to view row 2 as a Data Failure, and row 4 as a Non-matching row. Neither of these conclusions is strictly warranted - they are both guesses, or interpretations of the data sets. Note that row 2 could be a Non-matching row just as much as row 4 could be. Similarly, row 4 could be a Data Failure - there is no true way to tell without Shared Keys.
Data with No Keys – Duplicate Data
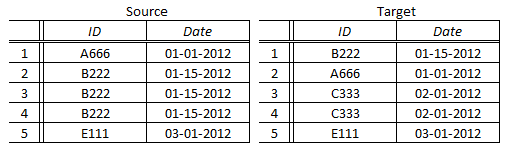
Finally, we come to our least favorable category – data where not only are there no keys, but there are no implicit keys either. This means that the data contains row duplicates. When data contains duplicate rows, it means that two (or more) rows are identical in every respect.
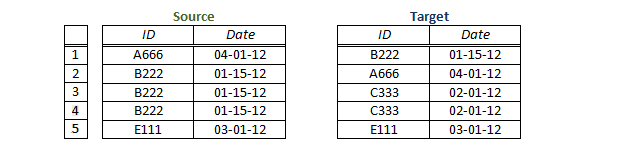
In the example above, the Source contains 3 duplicate rows (rows 2 – 4) and the Target contains 2 independent duplicate rows (rows 3 – 4). In addition, the Target contains a row identical to the 3 duplicates in the Source (row 1).
Handling Duplicate Data
If your resultsets contain duplicates, QuerySurge will detect this condition, and instead of trying to perform a row-by-row, cell-by-cell comparison as it does in other cases, it will turn to a statistical solution. QuerySurge will construct internally a histogram of Source and Target data, and then it will base its comparison on the histogram. In our case above, QuerySurge will calculate the following:

QuerySurge will then compare the ‘buckets’ and will decide that:
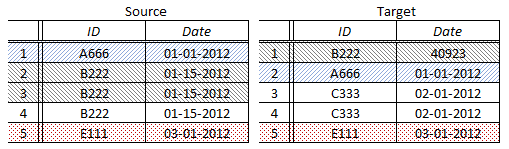
- Since the Source has a bucket (rows starting B222) with 3 members (frequency of 3) and Target has a matching bucket with 1 member (frequency of 1), there is an excess of 2 rows in this bucket on the Source.
- Both Source and Target have matching buckets with one member each for the rows starting A666 and E111. QuerySurge will assume that these are comparable and discard them since they match in both data and frequency.
- Target has a bucket (rows starting with C333) containing 2 members (frequency: 2), which have no match on the Source.
After comparison, QuerySurge’s (internal) bucket list looks like (cells without background remain after the comparison):

As we discussed previously, QuerySurge can’t really tell the difference between Non-matching rows and rows with Data Failures when no keys are identified. So QuerySurge will not score these rows as either category. All of the comments above concerning our assumptions about the “hidden” keys and what they could show about the relationships between the data apply to this situation as well.
Specifying Keys in QuerySurge
Keys are specified by column name in QuerySurge. On the Properties tab for any QueryPair, you’ll see the Key Column Definition section. You can use this section to indicate the name of the column (columns) that constitute a key for your data. If multiple columns are involved, provide a comma-separated list of column names. If your columns are aliased, you must use the aliases.
You must also indicate whether the column names you are using are from Source or Target. Based on this setting, QuerySurge will find the corresponding columns in the paired data source (if you specify Source key columns, QuerySurge will find the corresponding columns in the Target, and vice-versa). Remember, QuerySurge requires that your Source and Target columns are logically related (i.e., that column 1 Source is comparable to column 1 Target, column 2 Source is comparable to column 2 Target, etc.)
The example above is based on the following query, in which you can see that the second column constitutes a key:
SELECT o.IDORDER "Order ID", o.ORDER_IDCUSTOMER "Customer ID",
o.ORDER_IDORDERSTATUS "Order Status", o.ORDER_IDSHIPPINGRATE "Rate"
FROM Sales.Orders o
WHERE o.IDORDER <= 7 OR (o.IDORDER >=9 AND o.IDORDER <=13)
How Shared Key-based evaluations appear in QuerySurge
After you execute either a Design-Time Run or a full Scenario execution, you can drill down into your data. If you have identified keys for your QueryPairs, QuerySurge will categorize your data mismatches as either a Data Failures or a Non-matching row.
Data Failures are flagged with the light red highlighting and the 
 icon on the Failure tab in QuerySurge’s data drill-down.
icon on the Failure tab in QuerySurge’s data drill-down.
Non-matching rows are marked with the 
 icon and a red outline.
icon and a red outline.
 NOTE Data Failure highlighting is "key-naive;" it operates without knowledge of your key columns. The reason for this is that QuerySurge might have to order your data for the highlighting to make visual sense, if the Source and Target rows were not ordered identically. Because QuerySurge does not want to impose order on your rows beyond your control, QuerySurge makes the assumption that the order of the rows is the order you have chosen.
NOTE Data Failure highlighting is "key-naive;" it operates without knowledge of your key columns. The reason for this is that QuerySurge might have to order your data for the highlighting to make visual sense, if the Source and Target rows were not ordered identically. Because QuerySurge does not want to impose order on your rows beyond your control, QuerySurge makes the assumption that the order of the rows is the order you have chosen.
In the example below, there are 9 Data Failures (Source rows 1 – 9), and 3 Non-matching rows on Source with 1 Non-matching row on Target. These counts are provided in the Design-Time Run summary:

In the actual data popup Failure Tab, QuerySurge presents a detailed view of the comparison:

Note that, because there are Shared Keys in this example, QuerySurge can correlate the rows in its display - it skips a space in the Source display for the Target Non-matching row 8 - because there is no matching key for this row in the Source data. On the Target side, the last 3 rows are "open" (though this is not visible) because there are no matching rows on the Target for the final 3 Source rows.
How "Implicit" Key-based evaluations appear in QuerySurge
As we discussed above, because the situation without Shared Keys is profoundly different than with Shared Keys, there are some differences in presentation. The major difference is that QuerySurge will not try, by default, to pick out Data Failure or Non-matching rows. In addition, apparent mismatches are highlighted with a different background when Shared Keys are absent.

If you're interested in QuerySurge's guess about what the data mismatches are, you can select (View Options menu in the upper right) Show Inferred Data Mismatches:
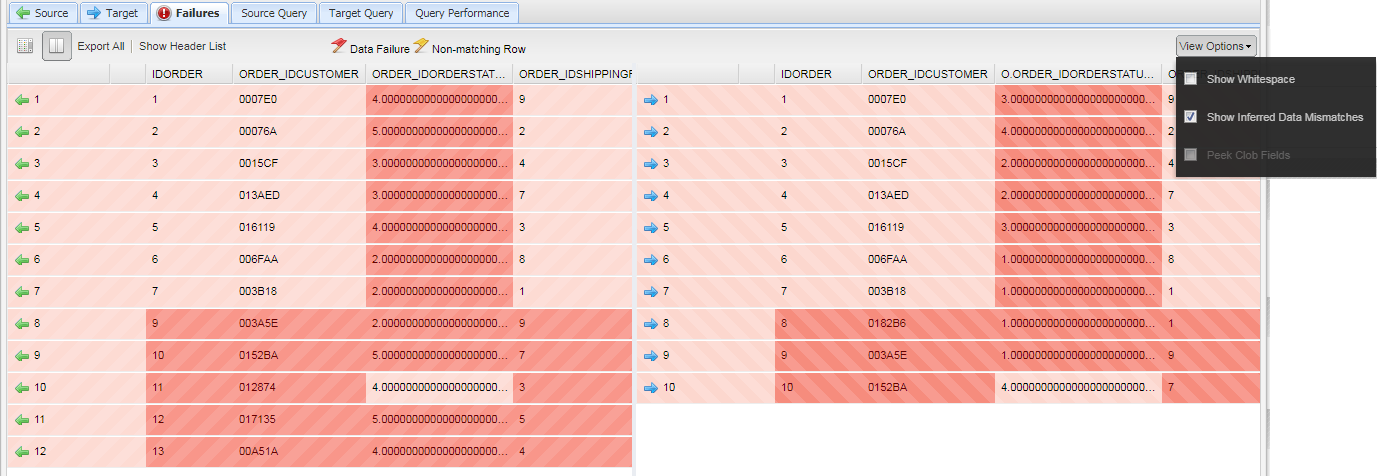
Note that this calculation uses row order as a proxy in its calculation, so you should order Source and Target queries accordingly. As this article goes to significant lengths to point out, you should view this guess critically - your data may not conform to its assumptions, and you could be mislead.