Versions:7.0+
BigQuery is Google's serverless, scalable, enterprise data warehouse. This article describes the use of QuerySurge with Google BigQuery to analyze data stored in BigQuery data sets and also data stored in Google cloud storage and Google drive.
Connecting QuerySurge to BigQuery
As with all data stores, QuerySurge connects via JDBC. Google has released a BigQuery JDBC driver in partnership with Magnitude Simba. You can find background and download links for the BigQuery JDBC driver here.
The BigQuery JDBC driver offers four OAuth-based authentication options (Service Account, Google User Account, Pre-generated tokens, Application Default Credentials. This article describes the process for connecting with a Service Account.
 Note: Authentication via Google User Account is not recommended for use with QuerySurge, as it requires user interaction with a JDBC driver GUI during query execution.
Note: Authentication via Google User Account is not recommended for use with QuerySurge, as it requires user interaction with a JDBC driver GUI during query execution.
Configuring BigQuery Authentication
The Google BigQuery JDBC Driver for uses the OAuth 2.0 protocol for authentication. There are four Google OAuth API methods to provide credentials and to authenticate a connection to the data warehouse. See the JDBC driver documentation for information about these authentication options. This article focuses on using a Google Service Account.
Create a Service Account
In the dashboard of your Google Cloud Platform project, using the navigation menu at the top left, select IAM & Admin, and then, in the drop down menu select Service accounts.
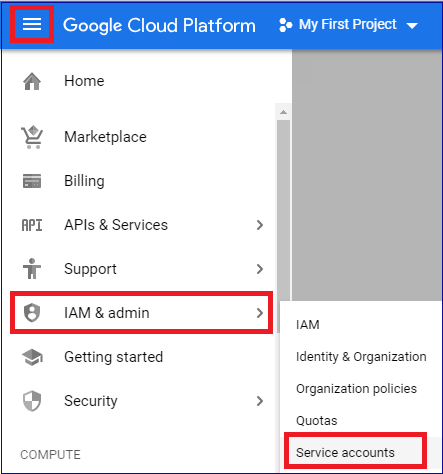
Create a new Service account by adding a name, ID and description. Assign a role to the BigQuery instance within your project, the minimum permission needed to query data is BigQuery User.
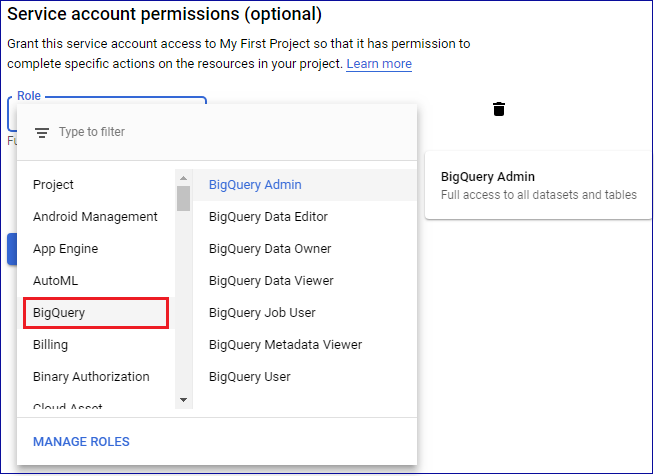
The account that creates this service account by default has access to its settings, you may add user access to the service account if needed. Once the Service account is created, note the account's Email address (which should have the following form):
<Service Account Name>@<Your Project ID>.iam.gserviceaccount.com
To add the Role go to IAM and Admin and click on IAM. Click Add in the top middle, then put the account's email address from above into the New members box. In the Role box type in BigQuery to filter and select at least the BigQuery User then click Save.
Generate the Key File
Next, download a key file for the Service account. In the Service Accounts tab, under the actions column of the service account you created, click the three dot dropdown and select Create Key. Simba supports both JSON and P12 key file formats.

 Note: The key file contains your private key. It is critical that the key file has appropriate access limitations once it is deployed, because connection security depends on it. Because you may need to deploy this file to multiple QuerySurge Agents, appropriate access on all Agent machines must be arranged. Note that key file access must be provided for the user under which your QuerySurge Agent(s) run. (See more information about Agents and the user logins under which they run here.)
Note: The key file contains your private key. It is critical that the key file has appropriate access limitations once it is deployed, because connection security depends on it. Because you may need to deploy this file to multiple QuerySurge Agents, appropriate access on all Agent machines must be arranged. Note that key file access must be provided for the user under which your QuerySurge Agent(s) run. (See more information about Agents and the user logins under which they run here.)
Deploy the Simba JDBC Driver Jars
For QuerySurge to use the BigQuery Simba JDBC driver, all the driver jars must be deployed to all QuerySurge Agents that you plan to use for BigQuery tests. The driver jars can be downloaded here.
To deploy drivers manually to your QuerySurge Agents, see this article for Windows and this article for Linux. The easiest way to get all of the jars is to extract the downloaded zip file to the QuerySurge\agent\jdbc folder for Windows or the /opt/QuerySurge/agent/jdbc folder for Linux.
Note: The 4.1 Simba drivers are only compatible with QuerySurge 5.0+ as they are compiled with Java 7. The 4.2 Simba drivers are only compatible with QuerySurge 6.4+ as they are compiled with Java 8.
Create a QuerySurge Connection to BigQuery
To create a new BigQuery Connection in QuerySurge, use the Connection Extensibility feature of the QuerySurge Connection Wizard. You can find a description of how to use Extensibility in this article.
The Driver class for the connection is:
com.simba.googlebigquery.jdbc42.Driver
The connection string format is:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;ProjectId=<Your Project ID>;OAuthType=0;OAuthServiceAcctEmail=<Service Email Address>;OAuthPvtKeyPath=<Path to Key File>;
Note: The <Path to Key File> parameter is the full path including the file name, not the directory path without the file name (for example: /home/keyfiles/keyfile.json)
Query Tables in BigQuery with QuerySurge
Tables can be queried by specifying the data set followed by the table in the FROM clause.
SELECT ... FROM <Data Set>.<Table Name>
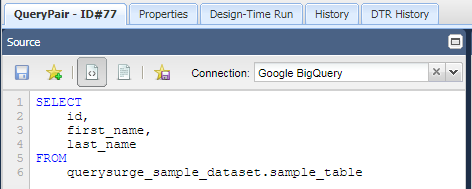
Note: Simba supports BigQuery's Standard SQL; a full guide can be found here.
Note: Keep in mind that the Simba driver returns all string values as CLOBs. Because QuerySurge respects the clob type (see this Knowledge Base article), users should consider implementing with casting to avoid multiple CLOB datatypes in your results.
Query Files in Google Cloud Storage with QuerySurge and BigQuery
BigQuery allows you to query data from files stored in Google Cloud Storage. First you need to create a table that points to your Cloud Storage location. In a data set of your choosing, select Create a new table.

In the menu for the create table from combo box, select Google Cloud Storage. Next, define the schema for the table. This can be done either manually or automatically.

Note: You can pull multiple files of the same type into one table by using the wildcard character (*) in the Select file from GCS bucket edit box. In the example above, if you have /sample001.csv, /sample002.csv etc. in your bucket, you can use /../sample* to pull all files matching the file name wildcard into one table. Note that these files all should have the same layout so that the same table schema applies across all the files.
Once a table has been created that points at the data in Cloud Storage, you can query it in QuerySurge like any other BigQuery table:

Query Files in Google Drive with QuerySurge and BigQuery
BigQuery also supports querying data from files stored in a Google Drive. The process is similar to querying files in Cloud Storage. A permanent external table in BigQuery must be created. First you'll need a Drive URI. In Google Drive, right click your file and click Get shareable link. The URI will be copied to the clipboard.
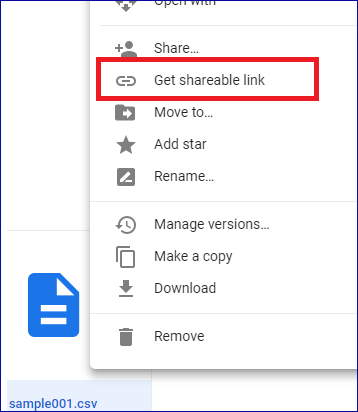
In a data set of your choosing select Create table.
In the menu for the Create table from combo box, select Drive. Paste the link into the Select Drive URI field and choose a file format.

Next, enter a table name and define your schema or allow Google to auto-detect it for you and create the table (not shown). Once a table has been created pointing at the data in Drive, you can query it in QuerySurge like any other BigQuery table:
We've shown here that connecting QuerySurge to BigQuery offers multiple avenues to access your data stored in Google Cloud Storage services using a standard SQL dialect. As mentioned earlier, the full guide for Google's standard SQL syntax can be found here.