Versions:5.0+
Amazon Athena is an interactive query service that allows users to analyze data in Amazon S3 using a standard SQL syntax. This article shows how to connect QuerySurge to Athena and query data hosted on S3.
Deploy the Athena JDBC Driver
For QuerySurge to connect to Athena, the Athena JDBC driver must be deployed to all Agents. The driver can be downloaded from the JDBC 41-compatible link found here.
To deploy drivers to your QuerySurge Agents, see this article for Windows or this article for Linux.
 Note: The JDBC 41 drivers are compatible with QuerySurge 5.x.x or higher (Java 7 compatible). The JDBC 42 drivers are compatible with QuerySurge 6.4.x or higher (Java 8 compatible).
Note: The JDBC 41 drivers are compatible with QuerySurge 5.x.x or higher (Java 7 compatible). The JDBC 42 drivers are compatible with QuerySurge 6.4.x or higher (Java 8 compatible).
Create a QuerySurge Connection to Athena
To create a new Connection in QuerySurge, use the Connection Extensibility feature of the Connection Wizard. You can find a full description of this procedure in this article. You'll need an Admin login to QuerySurge.
Navigate to: Administration > Connections > Add. Check "Advanced Mode" and choose "* All Other JDBC Connections (Connection Extensibility)" in the Data Source dropdown.
For the Driver Class, enter the following:
com.simba.athena.jdbc.Driver
The JDBC URL template for this driver is:
jdbc:awsathena://AwsRegion=[REGION];UID=[ACCESS KEY];PWD=[SECRET KEY];S3OutputLocation=[LOCATION]
To build your JDBC URL, you'll need a region code, an access key, a corresponding secret key, and an S3 Output location.
- The Region Code
The region endpoint of your Athena instance can be found in the top right of the web console. In the example below, note that the instance is based in US East (Ohio) which corresponds top the us-east-2 region code. To find the region code from a region name consult this listing.
- Your Access key and Secret key.
Under your user menu, select My Security Credentials. Under the Access keys (access key ID and secret access key) list item, click the Create New Access Key button to generate a new access key. We recommend downloading a key file so that you have a local copy of your Secret Key. The access key will be used in the UID field and the secret key will be used in the PWD field of the connection string.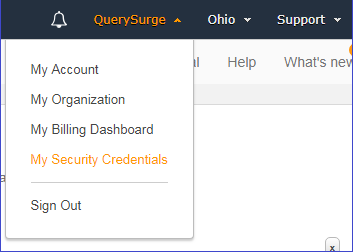
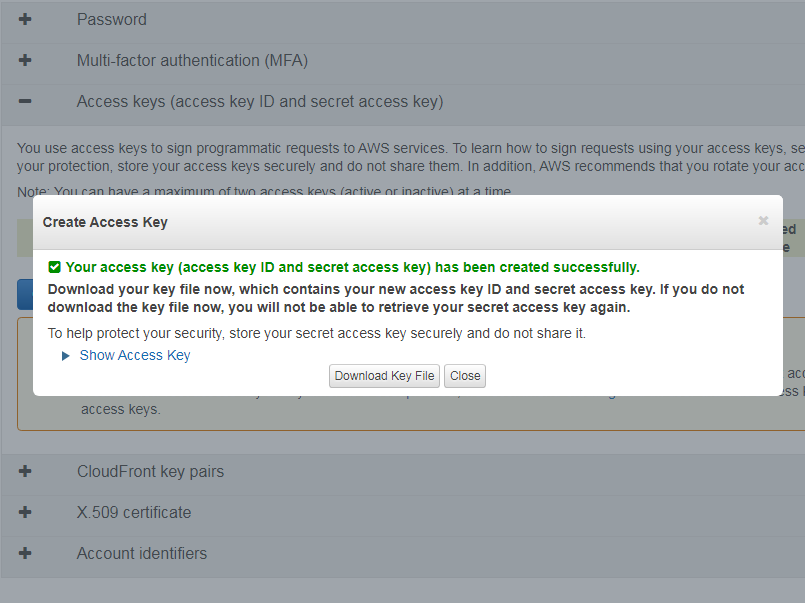 Note: This is the first and only time AWS will show your Secret Access Key. Store it in a safe location for later reference.
Note: This is the first and only time AWS will show your Secret Access Key. Store it in a safe location for later reference.
- The S3 Output Location
A query output location in S3 is required for the connection string. Athena caches all query results this location (more information can be found here). In this example, we use the directory test-results that we have created, residing in our sample-bucket on S3. This yields the following location s3://sample-bucket/test-results
The JDBC URL is:
jdbc:awsathena://AwsRegion=us-east-2;UID=1234ABCDE-1234-ABCD-5678EFGH;PWD=5678EFGH-1234-ABCD-1234ABCDE;S3OutputLocation=s3://sample-bucket/test-results
Test Your Connection
To test your connection from QuerySurge to Athena enter the query SELECT 1 in the Test Connection field, and click on the Test Connection button.
S3 Databases and Tables
To query files hosted on S3, you'll need to create both a database and at least one table in S3. To start this process, log into the Athena web console and select Query Editor.
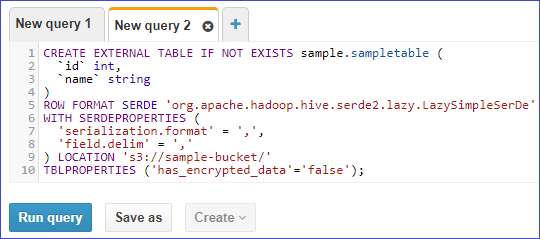
If there are no databases, you can create a database (called 'sample' in this example) with the following SQL statement:
CREATE DATABASE sample;
Once you have a database to work with, select the database you wish to use in the drop down menu then click Create Table. In the popup, select from S3 bucket data.

Choose a Table Name and the Location of Input Data Set; the location is a path to a directory in S3. Valid paths are of the format s3://bucket/folder/. In the following example, we use s3://sample-bucket/sample-folder/ as the location.
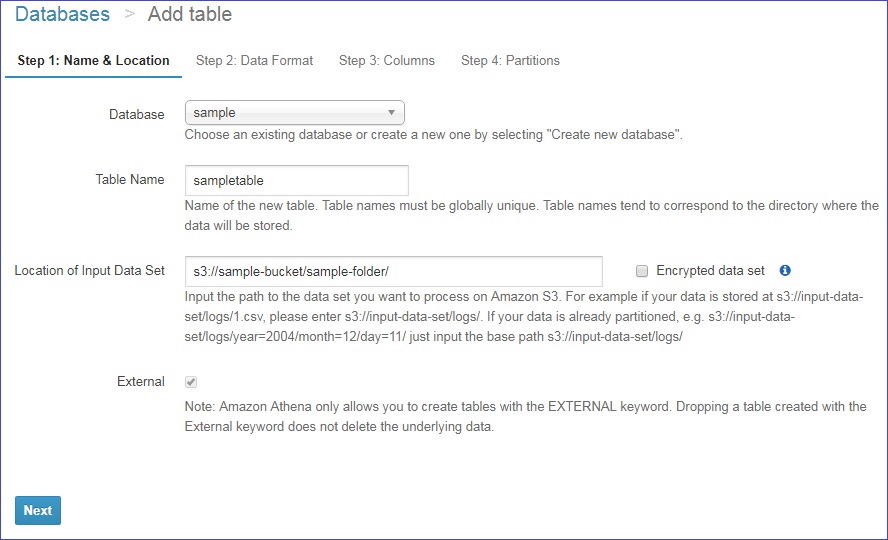
 Note: For this example, the sample file used is named sample.csv, located in the directory //sample-bucket/sample-folder/. Note that if there are multiple files of the specified type in the directory (in this case CSV), when you query, data will be extracted from all files in the directory and included in the result set.
Note: For this example, the sample file used is named sample.csv, located in the directory //sample-bucket/sample-folder/. Note that if there are multiple files of the specified type in the directory (in this case CSV), when you query, data will be extracted from all files in the directory and included in the result set.
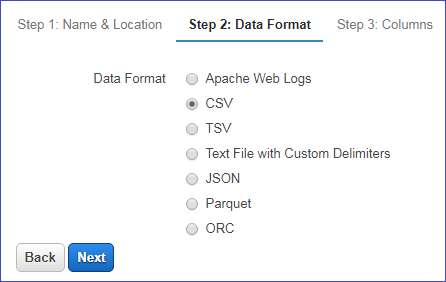
Next select a data format - in this example we use CSV files.
In step 3, columns can be added and defined for the table. Columns can also be added in bulk with the syntax (col_name data_type), for example (id int, name string). You may also add partitions if you'd like on the final step 4.
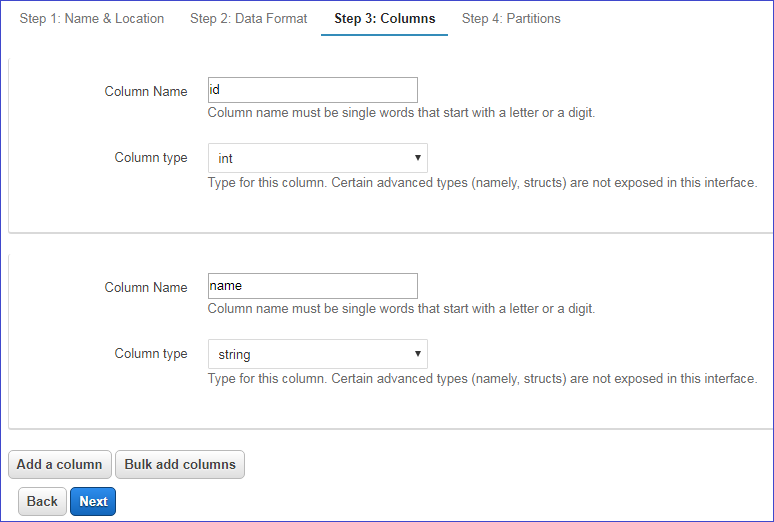
After these steps have been completed, select Save and ddl to create your table will be generated. Select Run query to create the table in Athena.
Querying S3 Data
Now, you can run a select statement to ensure the data is being pulled from the location specified. The result set returned will be shown in the Results section.

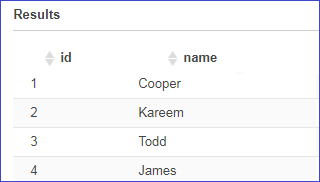
Note: Headers in flat files will be included in the result sets.
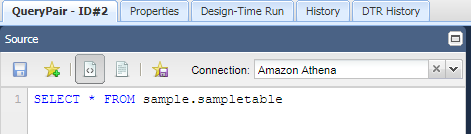
You are now ready to query the bucket data from QuerySurge. In the example below, we query all columns from the sample.csv file that is hosted on S3 and defined by sampletable in Athena.
Note: Documentation for Athena SQL syntax can be found here.