Dremio is a tool designed for querying a variety of structured and partially structured data stores via JDBC, including
- Azure Data Lake Store
- Amazon S3
- HDFS
- Hive
- HBase
- MongoDB
- Relational Databases (Postgres, MySQL, Oracle, SQL Server, DB2, Redshift)
- Files (Parquet, ORC, JSON, CSV, Excel)
In this article, we show how to set up a Dremio instance and to create a connection from QuerySurge to Dremio .
Installation for Linux
Dremio requires the 64-bit Java Development Kit version 1.8 on the host OS to run. Dremio supports the following distributions and versions of Linux:
- RHEL and CentOS 6.7+ and 7.3+
- SLES 12 SP2+
- Ubuntu 14.04+
- Debian 7+
You can download Dremio by obtaining the tarball and unpacking it with these commands:
wget https://download.dremio.com/community-server/<VERSION>/dremio-community-<VERSION>.tar.gz
tar -xzf dremio-community-<VERSION>.tar.gz -C /opt
Dremio is started with the following command:
>> cd /opt/dremio-community-<VERSION>/bin
>> ./dremio start
Once it has started, the Dremio web console will be visible at the following web address:
http://<serverNameOrIP>:9047
Installation for Windows
Dremio requires the 64-bit Java Development Kit version 1.8 on the host OS to run. You can download the Windows installer here. Once the installer has completed, you can run Dremio from the start menu. When the GUI opens select Start.

Once it has started, the Dremio web console is available at the following URL (on its host box):
http://localhost:9047
Apache Zookeeper
Dremio utilizes Apache ZooKeeper behind the scenes for cluster coordination. With no additional configuration, Dremio will automatically run an embedded zookeeper instance. However, if you wish to use an external zookeeper instance, add the following lines to the dremio.conf file in the $DREMIO_HOME/conf/ directory.
services.coordinator.master.embedded-zookeeper.enabled: false
zookeeper: "host1:2181" Note: host1 should be replaced by your zookeeper server name or IP address. If you wish to use Dremio's own Zookeeper instance then skip this step.
Note: host1 should be replaced by your zookeeper server name or IP address. If you wish to use Dremio's own Zookeeper instance then skip this step.
Deploy the Dremio JDBC Driver
For QuerySurge to use Dremio, the Dremio JDBC driver must be deployed to all QuerySurge Agents. The JDBC driver is named dremio-jdbc-driver-<VERSION>.jar and is located in /opt/dremio-community-<VERSION>/jars/jdbc-driver/
Once you have deployed the Dremio JDBC driver to your QuerySurge Agents, restart the Agents for this change to take effect. For full instructions on deploying JDBC drivers to an Linux agents, see this Knowledge Base article.
 Note: Dremio JDBC drivers above version 3.0.0 are only compatible with QuerySurge versions 6.4 or newer as they require Java 8. If your QuerySurge version is 6.3 or earlier you will need to user a Dremio JDBC driver earlier than 3.0.0.
Note: Dremio JDBC drivers above version 3.0.0 are only compatible with QuerySurge versions 6.4 or newer as they require Java 8. If your QuerySurge version is 6.3 or earlier you will need to user a Dremio JDBC driver earlier than 3.0.0.
Create a Connection
To create a new Connection in QuerySurge, use the Connection Extensibility feature of the Connection Wizard. You can find a full description of this procedure in this article. Key points include the following:
- You'll need to log into QuerySurge as a QuerySurge Admin user
- Navigate to: Administration > Connections > Add. Check "Advanced Mode" and choose "* All Other JDBC Connections (Connection Extensibility)" in the Data Source dropdown.
- For the Driver Class, enter: com.dremio.jdbc.Driver
- For the Connection URL, enter:
jdbc:dremio:direct=<Hostname>:31010
Note: The default port for Dremio coordinator is 31010, this should be changed if your port differs.
- For the Username and Password enter appropriate Dremio login credentials
- If you'd prefer to connect to a Zookeeper Quorum rather than the Dremio direct server then you can use the following connection URL:
jdbc:dremio:zk=<ZOOKEPER_QUORUM>:2181
Note: The ZOOKEEPER_QUORUM variable shown above should be replaced by your quorum hostname or IP address. Also note that 2181 is the default Zookeeper port, this should be changed if your port differs.
Dremio Console
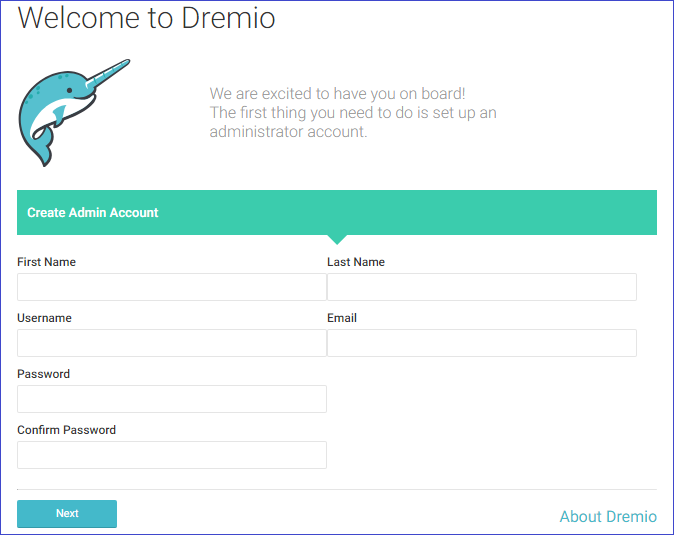
Your first time navigating to the Dremio web console, you will be prompted to create an admin account.
Once you create an account and log in, you will be shown to the dashboard. You can add a new data source on the left side of the dashboard by clicking the plus icon next to your Sources.
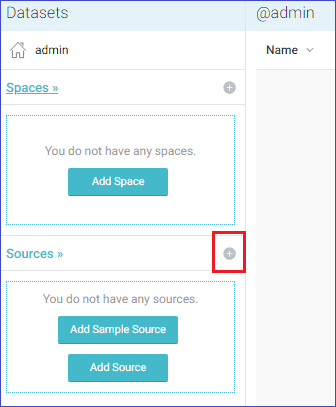
Dremio can connect to many data sources including relational databases, distributed filesystems and cloud storage. Dremio comes bundled with a Sample Source, which we use for the examples in this article.

Note: Dremio connects to a variety of data sources; for information, see these guides.
Once your connection is added, you will be able to see the added data store under Sources.
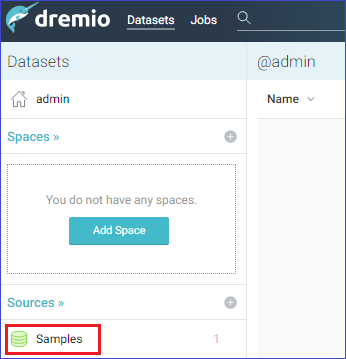
To be able to query the sample flat files within the Samples data source, they must be first represented as datasets in Dremio. To do this, click the dataset icon in the Action column:

In the example above, SF_incidents2016.json, zips_lookup.csv and zips.json are flat files in the Dremio sample data source. After Dremio's representation of the SF_incidents2016.json file is changed to a dataset representation, its icon changes to show the difference between the different members in the data source:

Now that the SF_incidents2016.json file is represented by a dataset, it is available to query using standard SQL in both the Dremio console and QuerySurge.
Querying Datasets in Dremio from QuerySurge
The following format is used to query datasets in Dremio.
SELECT ... FROM SOURCE.["PATH".]"FILE NAME"
Note: Each sub-directory in a path is separated by a period, not a forward slash; directories and file names must have double-quotes around each directory level.
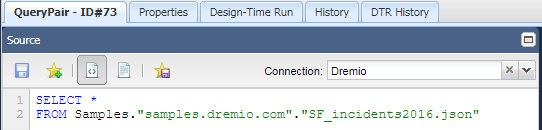
In the example below, we query a JSON file named SF_incidents2016.json from the path /samples.dremio.com directory of the Samples source.
In the example below, we query a CSV file named sample.csv from the path /samples/new in the Samples source.

Note: Dremio's complete SQL reference guide can be found here.